ES学习之全文检索原理
Elasticsearch是比较好用的全文搜索工具, 它是基于Lucene的, 本文简单介绍下全文搜索的一些内容
关于搜索
搜索就是从一堆数据里找我们想要的内容, 我们先对数据做个分类:
结构化数据: 具有固定格式或长度限制的数据, 如数据库非结构化数据: 也叫全文数据, 没有固定格式的数据, 如一篇作文, 一封邮件
此外还有半结构化数据, 如XML, HTML等, 按不同的数据分类, 搜索也分两类:
对结构化数据的搜索: 如数据库搜索, 使用SQL语句。全文搜索: 如grep命令, Google和百度对大量数据的搜索等。
全文搜索的方法
对全文数据进行搜索, 最简单的一种方式就是顺序扫描, 如果要找某个字符串, 则需要从头到尾开始找, 找到了则该文档就是我们要找的文档, 接下来再从下一个文档中搜索。这种方法最简单,单数据量大的时候效率十分低。
第二种方法是先把这些全文数据处理一下, 提取一部分信息重新组织, 让它变得有一定的结构。 这部分从非结构化数据中提取出的然后重新组织的信息,我们称之为索引。
因此通常全文检索分为两个过程: 创建索引(Index)和搜索索引(Search)。虽然创建索引的过程比较慢, 但索引创建之后可以多次使用,大大提高了搜索的效率。
倒排索引
在顺序扫描中, 我们是匹配文档是否包含我们所查找的字符串, 即从文档中找字符串; 我们想要的结果是哪些文档中包含要找的字符串, 即找到字符串到文档的映射, 两者恰恰相反. 所以如果索引能够保存字符串到文档的映射关系, 搜索就会变快, 这种保存字符串到文档映射关系的索引, 被称作反向索引或倒排索引.
假设我们有100篇文章, 三个字符串lucene,solr,hadoop分别出现在不同的文章中, 我们创建的反向索引如下图:
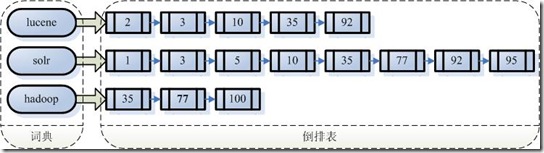
左边的字符串一般称为词典, 右边是包含该字符串的文档(Document)组成的链表, 成为倒排表(Posting List)
我们利用反向索引查找即包含lucene, 又包含hadoop的文档, 只需要通过字典找到两个链表, 把链表中相同的文档取出即可.
创建索引
- 第一步: 把文档(
Document)传给分词组件(Tokenizer)
这个过程会把文档Document分割成一个个的单词, 去掉标点, 去掉停顿次(the, a, this等), 经过分词得到的结果成为词元(Token).
- 第二步: 把词元(
Token)交给语言处理组件(linguistic processor)
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理, 比如变为小写(lowercase), 复数变为单数(stemming), 过去式变为原型(lemmatization)等。语言处理组件的结果被称为词(Term).
- 第三步: 把词(
Term)传给索引组件(Indexer)
索引组件利用词(Term)生成一个字典, 按字母顺序进行排序, 然后合并相同的Term成为文档的倒排链表
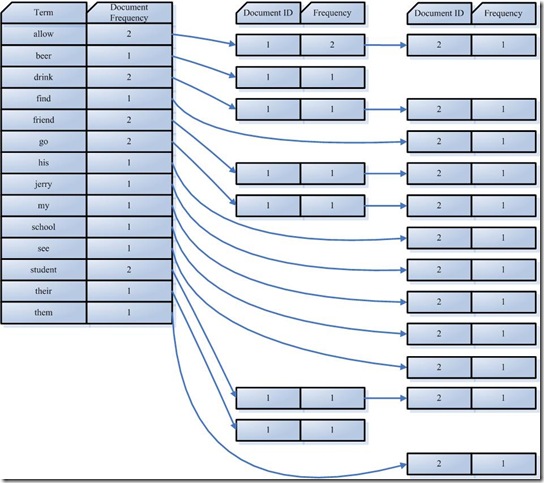
其中:
Document Frequency: 文档频次,表示总共有多少文件包含此词(Term)Frequency: 词频率,表示此文件中包含了几个此词(Term)
搜索索引
- 第一步: 输入查询语句
查询语句一般会有一定的语法, 比如lucene AND learned NOT hadoop, 表示搜索包含lucene和learned但不包含hadoop的文档
- 第二步: 对查询语句进行词法分析, 语法分析, 及语言处理
词法分析主要用来识别关键词和要搜索的单词, 比如例子中关键词有AND和NOT;
语法分析主要用来生成语法树, 不满足语法规则的则报错;
语言处理跟创建索引中几乎一致, 比如learned变为learn;
经过第二步处理, 得到一个经过语言处理的语法树
- 第三步: 搜索索引, 得到符合语法树的文档
首先,在反向索引表中,分别找出包含lucene, learn, hadoop的文档链表
其次,对包含lucene, learn的链表进行合并, 得到既包含lucene又包含learn的文档链表
然后,将此链表与hadoop的文档链表进行差操作, 去除包含hadoop的文档
最后, 此文档链表就是我们要找的文档
- 第四步: 根据文档和查询语句的相关性,对结果进行排序
这一步要先根据相关性进行打分, 得分高的排序靠前.