Hadoop项目框架
Hadoop相关项目的介绍
Hadoop框架图
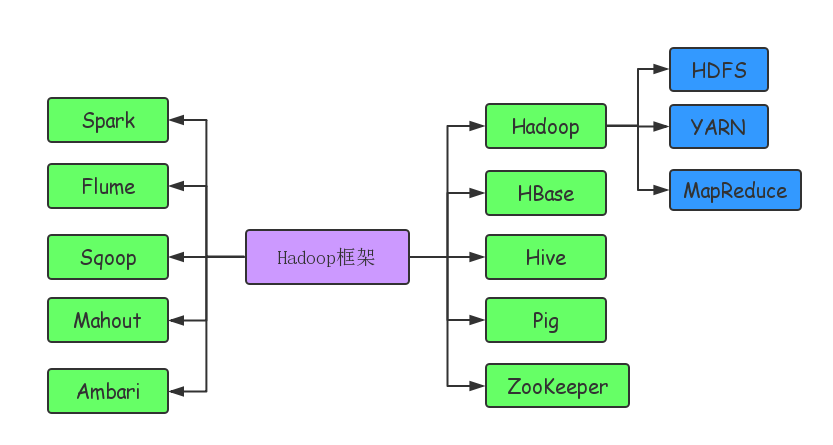
Hadoop
Hadoop是大数据的基础,它有4个模块 Hadoop Common, Hadoop Distributed File System (HDFS), Hadoop YARN和 Hadoop MapReduce
- HDFS
分布式文件系统, 适合存储大文件, 不适合小文件, 它的原理 这篇文章 讲的比较详细
- YARN
YARN(Yet Another Resource Negotiator), 任务调度和集群的资源管理, Hadoop2.0提供的革命性功能, 可参考这篇文章
- MapReduce
MapReduce本身是谷歌推出的一个编程模型, 包括Map和Reduce两个过程.
比如要计算1到10的平方和, 耗时较多的是计算平方, 加和耗时较少, 那么可以把整个过程这么拆分:
- Map, 即把计算平方的任务分给10台机器,每台机器分别计算平方, 然后Map的结果就是一个可迭代的集合, 就是这10个数的平方;
- Reduce, 即把Map的结果迭代加和, 得到最终结果
Hadoop MapReduce是MapReduce的一个实现, 2.0之后推出了基于YARN的Hadoop MapReduce
HBase
非关系型数据库, 面向列存储, 理解成 Key->Value 的存储更形象, 有行键(RowKey), 列族(Colum Family), 限定符(qualifier)等概念
列名(Column)是由列族前缀和限定符(qualifier)连接而成, 如列族d有两个列(限定符):title和content, 则列名分别为d:title、d:content;(row, column, version)唯一确定一个cell, 里面放着Value;
更多内容参考这里
Hive
是一个数据仓库工具, 可以将结构化的数据文件(hive文件,hbase)映射为一张数据库表, 然后通过SQL查询, 背后还是变成了MapReduce程序执行. 这种查询是秒级或分钟级的, 比较慢.
Pig
和Hive类似, 有自己的查询语法
Sqoop
一个ETL工具,可以进行数据同步, 比如把Oracle、Mysql等关系型数据库中的数据导入到HBase中、HDFS上, 也可把数据从HDFS或HBase导入到Mysql中
Flume
日志收集工具
ZooKeeper
分布式协作服务, 好多地方都会用到, 比如写了个dubbo服务部署到5台机器上, 统一交给ZK进行管理, 使用者就不用关心到底调用哪台机器上的服务了. 具体内容可参考这里
Spark
这东西很火, 是一个内存计算的框架, 目前一个大的趋势. MapReduce会有很大的IO操作, 而Spark是在内存中计算, 所以很快
Mahout
一个数据挖掘和机器学习的库, 搞数据挖掘的用的比较多
Ambari
一个基于Web的管理平台,可以对集群进行统一的部署